Data da publicação: 20/09/2025.
Neste tutorial vou mostrar de forma prática como consumir mensagens do Kafka paralelamente com Spring Boot
1 Criando o tópico e produzindo as mensagens
Esse tutorial vai ser uma continuação do outro tutorial em que eu mostrei como criar a primeira conexão com o Kafka via Spring Boot, então irei considerar que você já saiba como que funciona o básico dessa integração. Além disso é bom você também ter visto como criar sua primeira API.
Os passos iniciais são criar uma aplicação que possua as dependências Web, Actuator e Kafka do Spring Boot e subir o servidor do Kafka no Docker, ou então configurar o application.properties para apontar para o servidor do Kafka, caso ele não esteja rodando localmente.
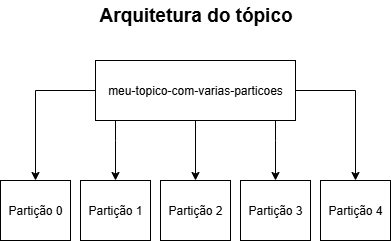
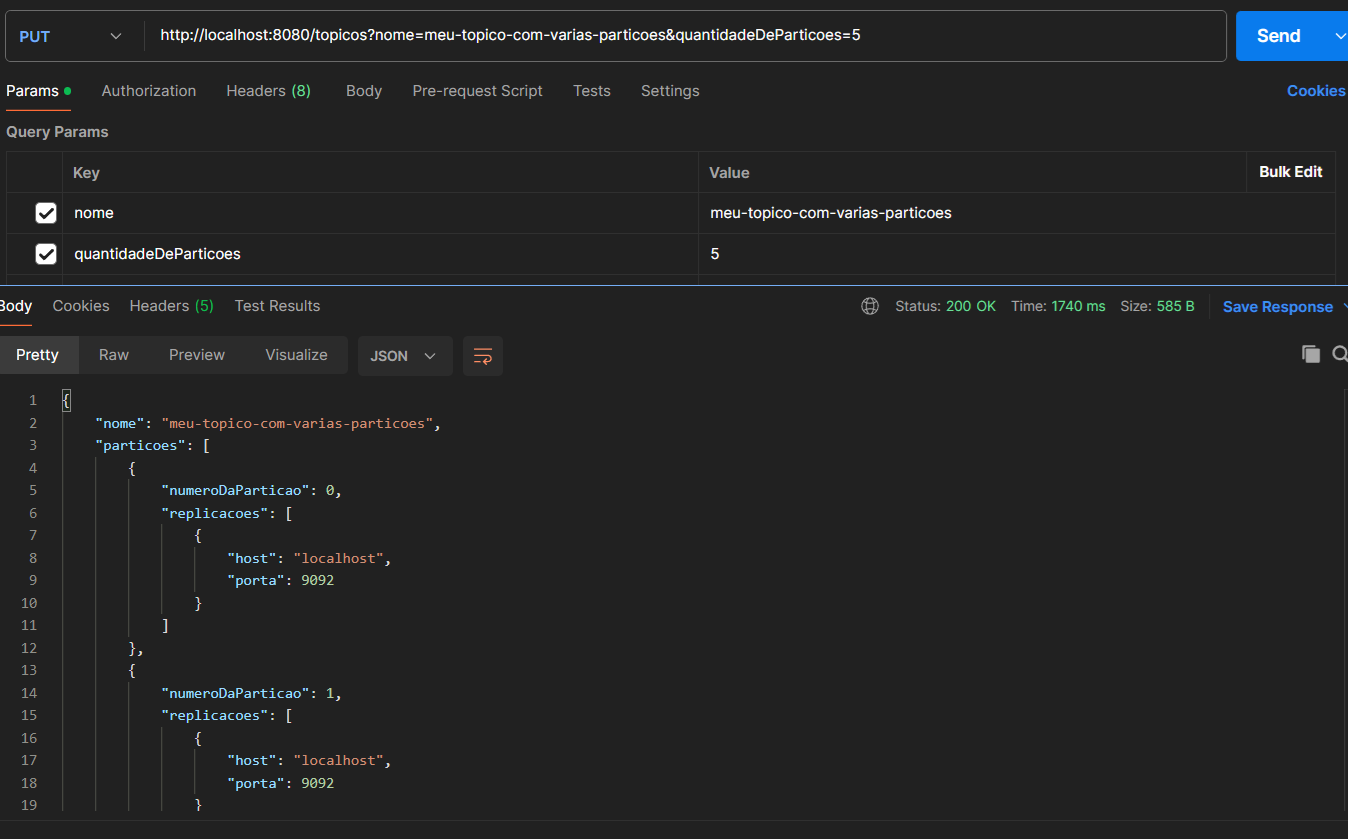
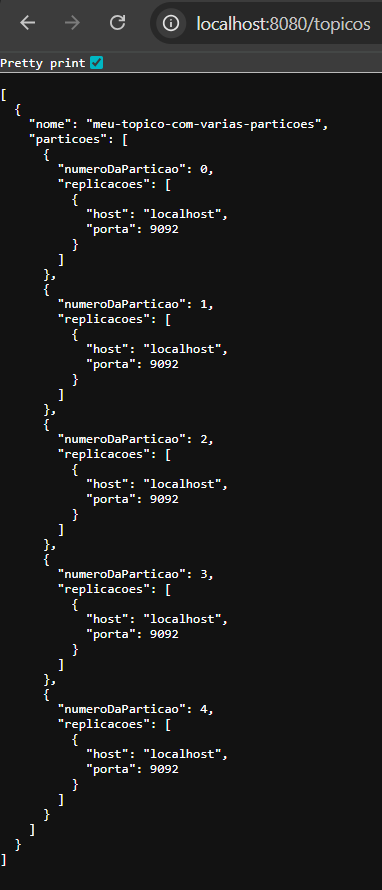
Feito isso, crie um tópico chamado "meu-topico-com-varias-particoes" com 5 partições. Como dito no tutorial "Como criar tópicos no Kafka", para cada partição podemos ter um consumidor, então nesse caso poderemos "plugar" nesse tópico até 5 consumidores em paralelo, porém todos devem ter o mesmo group id. O group id é um identificador utilizado pelo Kafka para controlar os consumidores que serão executados em paralelo, evitando que mais de um deles receba a mesma mensagem, garantindo assim a entrega da mensagem apenas 1 vez por group id. O último ponto importante de lembrarmos é que, caso coloquemos um sexto consumidor, esse sexto consumidor não conseguirá "se plugar" no tópico, sendo assim ele ficará desconectado e só irá ser conectado caso um dos consumidores já conectados desconecte.
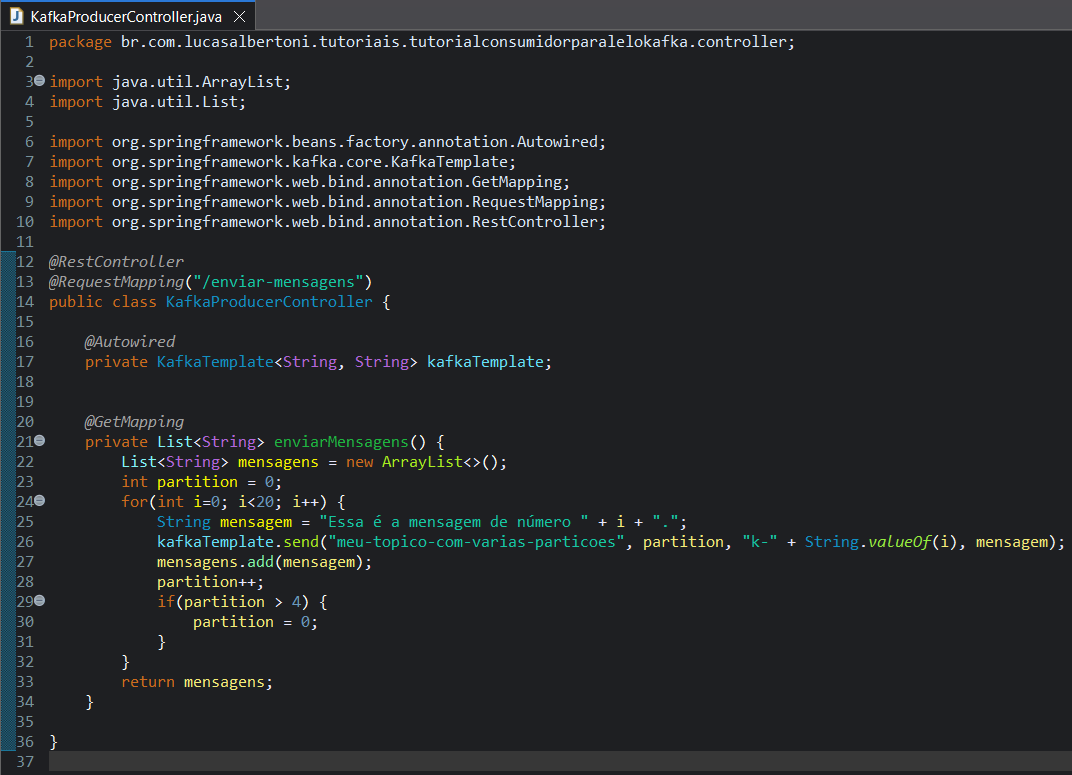
Criado o tópico agora podemos produzir mensagens para ele. Como o foco desse tutorial é no consumidor, então crie um pacote "controller" e dentro dele crie a classe "KafkaProducerController", anote essa classe com "@RestController" e "@RequestMapping("/enviar-mensagens")". Adicione o atributo privado da classe "KafkaTemplate" com parâmetros de String e String e de o nome de "kafkaTemplate". Então crie um método público que retornará uma lista de String e não receberá nenhum parâmetro com o nome de "enviarMensagens" e anote ele com "@GetMapping". Dentro desse método crie um looping de 0 até 19 e envie uma mensagem para o kafka com o conteúdo de "Essa é a mensagem de número i.", onde "i" será a variável que estará contando a execução do looping, ainda nesse método de envio utilize o método que especifique a partição para garantir a utilização de todas as partições, no meu caso eu utilizei uma variável para controlar o número da partição, porém nesse método você será obrigado a passar uma chave String, e no meu caso eu passei ""k-" + String.valueOf(i)" e após o envio adicione essa mensagem em um lista e retorne a mesma.
Agora execute sua aplicação e chame o endpoint "http://localhost:8080/enviar-mensagens" pelo Chrome.
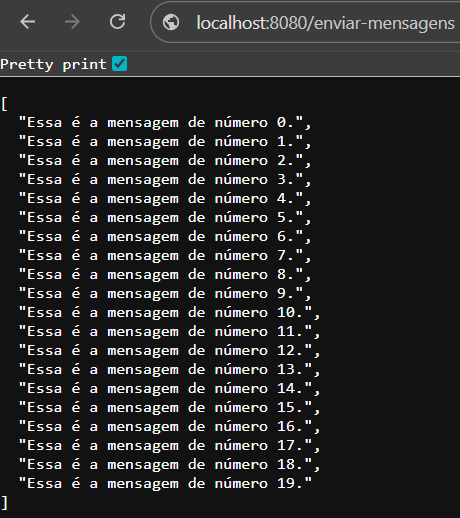
Pronto, agora podemos avançar para o consumo das mensagens.
2 Consumindo mensagens
No lado do consumidor, primeiro devemos adicionar duas propriedades no arquivo "application.properties", uma para definir o group id do consumidor que é "spring.kafka.consumer.group-id" e outra para definir que queremos que nosso consumidor receba todas as mensagens desde a primeira mensagem produzida, essa propriedade é "spring.kafka.consumer.auto-offset-reset" e coloque como valores dessas propriedades como "tutorial-consumidor-paralelo-kafka" e "earliest".
Essas duas propriedades serã suficientes para você conseguir criar um "KafkaListener", porém o intuito desse tutorial é criar consumidores em paralelos, no nosso caso queremos que a aplicação rode cinco consumidores um em cada Thread. Thread é a forma que o Java utiliza para executar processos em paralelo, fazendo assim que consigamos aumentar a performance da nossa aplicação, contudo precisamos tomar cuidado quando trabalhamos com Threads, pois com isso provavelmente nossa aplicação consumirá mais recursos computacionais, como memória e CPU.
Para implementar consumidores em paralelo basta adicionar uma terceira propriedade no arquivo "application.properties" que é a propriedade "spring.kafka.listener.concurrency" e como valor devemos colocar a quantidade de consumidores paralelos queremos (quantidade de Threads que serão criadas) e no nosso caso queremos 5.
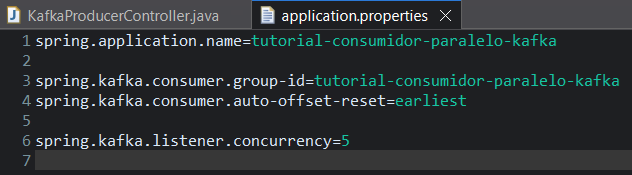
Com o arquivo "application.properties" configurado, agora precisamos criar nosso consumidor, e basicamente ele será igual o outro tutorial de integração do Kafka com Spring Boot.
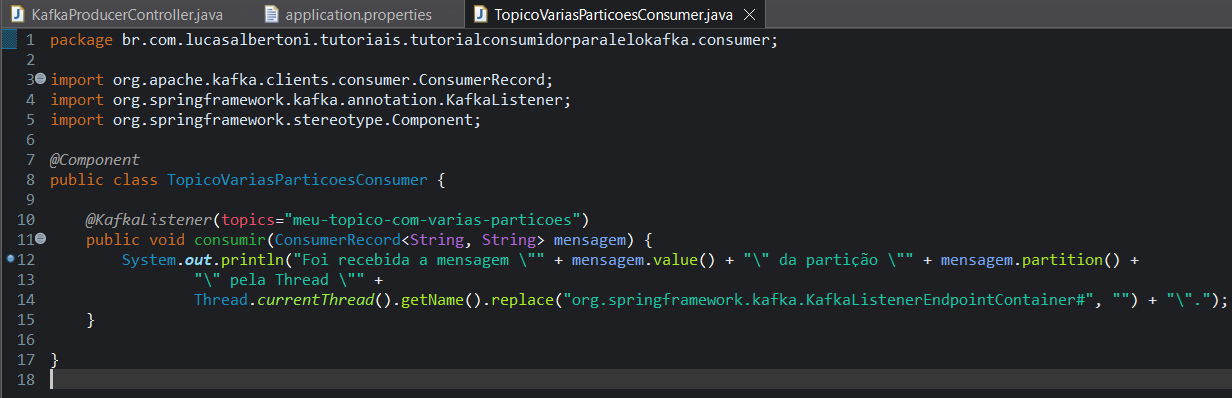
Crie um novo pacote chamado "consumer", dentro desse novo pacote crie crie a classe "TopicoVariasParticoesConsumer" e dentro dessa classe crie um método público void chamado "consumir". Esse método deve receber um parâmetro da classe "ConsumerRecord <String, String>" e de o nome dessa variável de "mensagem". Estamos recebendo esse tipo de objeto ao invés de um String, pois queremos saber mais informações sobre a mensagem ao invés de apenas o conteúdo dela, no tutorial anterior nós havíamos recebido apenas uma String, pois estávamos interessado apenas no conteúdo do corpo da mensagem.
Anote o método com "@KafkaListener( topics = "meu-topico-com-varias-particoes" )", e dentro do corpo do método vamos adicionar uma linha com um "System.out.println", passando como String as informações do corpo da mensagem (mensagem.value()), a partição de onde ela veio (mensage.partition()) e também a Thread que esta executando a leitura da mensagem (Thread.currentThread().getName()). Em relação a Thread, vamos remover o nome da classe para ficar uma melhor apresentação no log (.replace("org.springframework.kafka. KafkaListenerEndpointContainer#", "")).
O corpo inteiro do método ira conter: "System.out.println("Foi recebida a mensagem \"" + mensagem.value() + "\" da partição \"" + mensagem.partition() + "\" pela Thread \"" + Thread.currentThread().getName().replace("org. springframework. kafka. KafkaListenerEndpointContainer#", "") + "\".");"
Por fim, execute sua aplicação novamente, então você verá que no log aparecerá as mensagens que foram produzidas previamente, além disso irá observar que as mensagens não serão apresentadas na ordem e que existirão 5 nomes de Threads diferentes aparecendo e cinco partições diferentes, e por último você também pode observar que cada Thread ficou responsável por uma partição, ou seja, para a partição 0 terá uma Thread, para a partição 1 terá outra Thread e assim por diante.
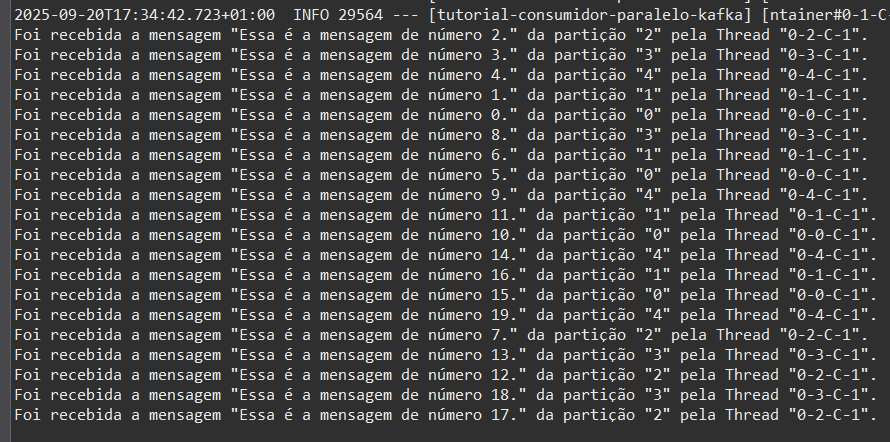
Veja que na minha execução, a partição "0" ficou para Thread "0-0-C-1", a partição "1" ficou para Thread "0-1-C-1", a partição "2" ficou para Thread "0-2-C-1", a partição "3" ficou para Thread "0-3-C-1" e a partição "4" ficou para Thread "0-4-C-1" e com isso concluímos o tutorial.
Conclusão
Após fazer esse tutorial você conseguiu entender como funciona os tópicos, partições e consumidores do Kafka, também entendeu como implementar consumidores paralelos através das partições e de propriedades do Spring Boot, ou seja, você viu que com uma único aplicação é possível paralelizar o consumo de mensagens do Kafka, porém você viu que esse consumo não seguirá a ordem de produção. Parabénss por mais um tutorial concluído!!!!! Espero que eu tenha te ajudado e até a próxima!!